Questions are so important when fault-finding; the more data you have, the more visibility you have of the situation.
What, Where, When
If you know what failed, where it failed, and/or when it failed then extraneous data can be discarded if it doesn’t match the answers to these questions.
Would you really want to discard data? Surely the more data you have the better? Well, yes, to a point. But the objective is to find the fault; anything else is noise and may distract from the objective.
Why
This is the answer you really want; you might know the what, the where, and the when, but until you can explain why you cannot fix the problem. Fault finding is about taking the what, where, and when, and coming up with the why.
How
How you fix the issue is up to you; if you know why a system doesn’t work then you have many options of how to deal with that problem. It might involve replacement, repair, or just plain ignoring the issue if it isn’t worth addressing.
In a country as big as Australia the speed of light becomes a limiting factor that can adversely affect customer experience. I’ll explain how.
Round-trip time is the time it takes for a network packet to travel from a local device to a remote device via a network, and for another packet to travel back from the remote device to the local device.
Various factors can affect how long it takes to transmit a packet. Large packets are limited by network speed (a 64 kilobyte packet takes ~640 milliseconds to transmit on a 1 megabit/second link). So faster links can transmit more data more quickly, naturally.
But, even with the fastest links, network latency (round-trip time) becomes an important factor when distance is involved. No packet can travel faster than the speed of light.
Consider the round-trip time at the speed of light between the following cities:
From
To
Kilometres
RTT1
Melbourne
Sydney
878
4ms
Melbourne
Brisbane
1,667
8ms
Melbourne
Perth
3,418
17ms
Melbourne
Singapore2
6,026
30ms
Melbourne
Tokyo2
8,144
41ms
Melbourne
London2
16,904
84ms
Notes:
1. Round-trip time calculated as Google maps driving distance between two locations multiplied by 2 divided by 200,000km/s
Those round-trip times are idealised best cases and real-world experience will be considerably worse than that taking into account all the routers a packet must traverse, congestion, transmission speed, and more.
Consider the scenario where you are loading a web page hosted in Perth on a computer in Melbourne. Ignoring 3-way TCP handshake and transmission times a typical modern complex JavaScript-based webpage with separate round-trip requests for 50 URLs would require:
50 x 17ms = 850ms
That’s not too bad, under a second, and a typical web browser will use concurrency to fetch those requests 4 at a time bringing that number down to ~212ms.
But what if that same website was in London? Then you’re looking at a minimum round-trip time (including concurrent downloading) of 1.0s.
Some websites get considerably more complex. For example, when this article was composed, The Age’s website required a browser to make 227 requests.
For the most part websites can often “get away” with many individual requests because they tend to be oriented towards local users or use a global content delivery network (CDN) to cache content closer to the user; in addition browsers cache a lot of unchanging content themselves such as style sheets and JavaScript code. But customers of localised sites on holidays overseas can still suffer when trying to access their accounts.
There are situations where a client program, however, does not conduct requests in parallel (no parallelism). I’ve seen this with the CORBA protocol which, because of its nature, requires request-response pairs to be serialised.
If you have a CORBA server, and expect to use a CORBA application client, and a login process makes 1,000 odd requests, then even if the locations involved are Melbourne to Sydney (4ms round-trip) then you’re looking at an absolute minimum of that process taking 4s. If that same process is used between Melbourne and Perth then the absolute theoretical minimum time would be 17s – not even taking into account other factors.
Latency has a serious impact on any non-trivial communication process and always has to be considered when delays present themselves.
Perhaps you are a CEO or CTO of an organisation that has contracted services out to one or more suppliers. And things are not going as smoothly as desired.
You may be looking for independent analysis.
Even if you already have a report on your desk from your vendor outlining potential issues – it might pay to have an independent viewpoint that you can take to your board as further evidence action is required.
IT Fault can evaluate your systems and provide you that independent technical report. Call today to arrange an evaluation of your systems.
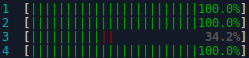
It was a curious thing. A website had been deployed to powerful production servers. These servers had many CPU cores.
Three CPU cores busy Yet every morning the system administrators would notice several processes using 100% cpu utilisation. At first it was just one or two rogue web application processes which could be easily killed off. But as the days went by more and more processes would be spinning at 100% CPU utilisation each morning.
Immediately I became suspicious of the application code; and I requested to see any and all code with while loops in them.
What is risky about while loops?
Let me digress for a moment. Why would I be suspicious of while loops?
The issue is that, unlike other kinds of loops, such as the for loop, a while loop relies on the programmer to update the condition variable inside the loop code.
A simple while loop is difficult to get wrong. For example:
This code will always complete because counter will always reach numusers eventually and cause the loop to end.
The counter variable is the “condition variable” for this loop because the while loop has a condition dependent on the counter variable. And this loop does, indeed, update the condition variable every iteration (by the counter++; statement).
The problem lies in larger organisations when multiple people are making changes to source code – perhaps when making a fix in response to a bug report. They may add some code like this:
/* iterate through users */
counter = 0;
while ( counter < numusers ) {
/* bug report 14132 - ignore user "secretuser" */
if ( strcmp( user[counter], "secretuser" ) == 0 ) {
/* match! loop again to avoid printing secretuser */
continue;
}
printf( "User %s\n", user[counter] );
counter++;
}
Now we have a problem. If "secretuser" appears in the user[] array then counter will no longer be incremented and the while loop will continue forever.
A for wouldn’t have this issue. Imagine if the loop had started out as:
/* iterate through users */
for ( counter = 0; counter < numusers; counter++ ) {
/* bug report 14132 - ignore user "secretuser" */
if ( strcmp( user[counter], "secretuser" ) == 0 ) {
/* match! loop again to avoid printing secretuser */
continue;
}
printf( "User %s\n", user[counter] );
}
The fact that counter was incremented in the for loop declaration ensures this loop will complete even though the maintainer added a continue statement inside the loop.
Thus for loops offer greater protection against accidental infinite looping.
A tight while loop is bad
If a CPU finds itself in the situation where it is in a tight while loop things can be worse than one might ordinarily expect. That’s because it might never find itself calling an operating system function – which would give the operating system a chance to consider whether anything else needs to be done (outside the application) – before returning control to the program.
Instead the CPU is executing instructions furiously over and over again – until a scheduled timer interrupt forces the CPU to visit the operating system and something else is given a chance to run.
So things are not utterly dire – other code does get a chance to run on the processor. But it’s not well behaved and polite like most programs are. Still, this kind of impolite hogging of the CPU does have consequences and is worth being aware of.
Back to the story
My suspicion was confirmed whereupon I found a while loop that had a rogue continue statement without any accompanying code to update the condition variable.
Quite simply I started grepping for the string continue and closely reviewed any while loop that contained the keyword. And that is how I found the fault.
Indeed it had been a bug fix. And was only triggered occasionally because it added an exception to the normal operation. In testing this exception had not been encountered.
But in production the exception was being triggered on occasion by real customers – and when it did their web session froze (never responded) and the process locked up at 100% CPU utilisation each time.
It was fortunate this issue was identified, and fixed, before whole servers became overwhelmed with CPU load.
A company had an issue with a website simply failing to perform. When load tested it could handle far fewer requests per second than were expected for the amount of hardware thrown at the problem.
The system had a front end web service for customers. It had a back end system that stored data the front end needed.
My investigations led me to more closely observe the interaction between the front and back ends. I found that every front end only had two TCP connections to each back end server – which was fewer than I expected for a fully loaded system.
I knew the front end was coded in Java – so started looking into what classes they were using to make web requests to the back end. And there I found the fault: the customer was using the Apache HTTP Components library and, in particular, the PoolingHttpClientConnectionManager class.
This class was clever in that it “pooled” HTTP connections to allow for more efficient use of existing connections. The problem was clear in the documentation that, by default:
Per default this implementation will create no more than than 2 concurrent connections per given route
I informed the development team and they expanded the maximum number of concurrent connections to the back end service.
Subsequent performance testing confirmed this was, indeed, the issue, and the front end began handling the expected load again.
A specialist is somebody that knows more and more about less and less until they know everything about nothing.
A generalist is somebody that knows less and less about more and more until they know nothing about everything.
Like most good jokes there’s a grain of truth to it. But joking aside why is an “experienced generalist” somebody you want hunting down a fault for you?
In most organisations employees are tasked with a particular aspect of a complex system, for example:
your developers are dealing with a set of APIs – in the Java world this might be Hibernate, Spring, or an Apache connection pooling library
your system administrators are dealing with rolling out code – often to development environments first and then production environments
your virtual machine team is dealing with creating and destroying virtual machines – as requested by the project and managing resource utilisation
your devops team is dealing with another set of APIs – be they cloud related or managing the installation and upgrade of physical hardware your company owns
Each of these is often focused on their particular area of expertise and responsibility. And as much as one might try and refrain it is all to easy to blame another team when something goes wrong.
A generalist may not know the specific APIs your team is using. They may not know the specific limits of your hardware. But they’ve been around long enough to build up the skills to find out what needs focus.
That generalist will then pour through documentation and other material available to match recognised symptoms with potential problems – then hone in to eliminate potential areas of trouble.
The generalist will discount nothing! And they do not need to defend a specific aspect of a system. They are free to consider all the possibilities. And sometimes the results are quite surprising! But they are stories for a different day.
I am proud to introduce my personal problem-identifying service for clients in Melbourne and surrounding suburbs.
Taking my wealth of experience into account I realised that the skill I have to offer is that of pinpointing problems – which I have so frequently done everywhere I’ve worked.
I have an intuitive knack for isolating the fault by methodically understanding and verifying components of complex systems are doing what they should be doing.
The intuition is bolstered by years and years of experience. Absorbing knowledge from books as well as real-life situations where a business-critical function failed and the service needed to be brought back online urgently!
If your company is facing the very real prospect of incurring a heavy financial penalty from a system’s downtime then don’t hesitate. E-mail me (rather than phone) and I will get back to you – we can discuss your symptoms and how I might be able to help.
I’m not providing a resolution service. I’m not here to replace components, to upgrade your database, or to develop a new accounting system for you. I’m here to help your teams understand what has gone wrong so they can take action to fix it.
It’s finding the cause of a problem that’s so often the hard part. Let me help you with that.


 Perhaps you are a CEO or CTO of an organisation that has contracted services out to one or more suppliers. And things are not going as smoothly as desired.
Perhaps you are a CEO or CTO of an organisation that has contracted services out to one or more suppliers. And things are not going as smoothly as desired.